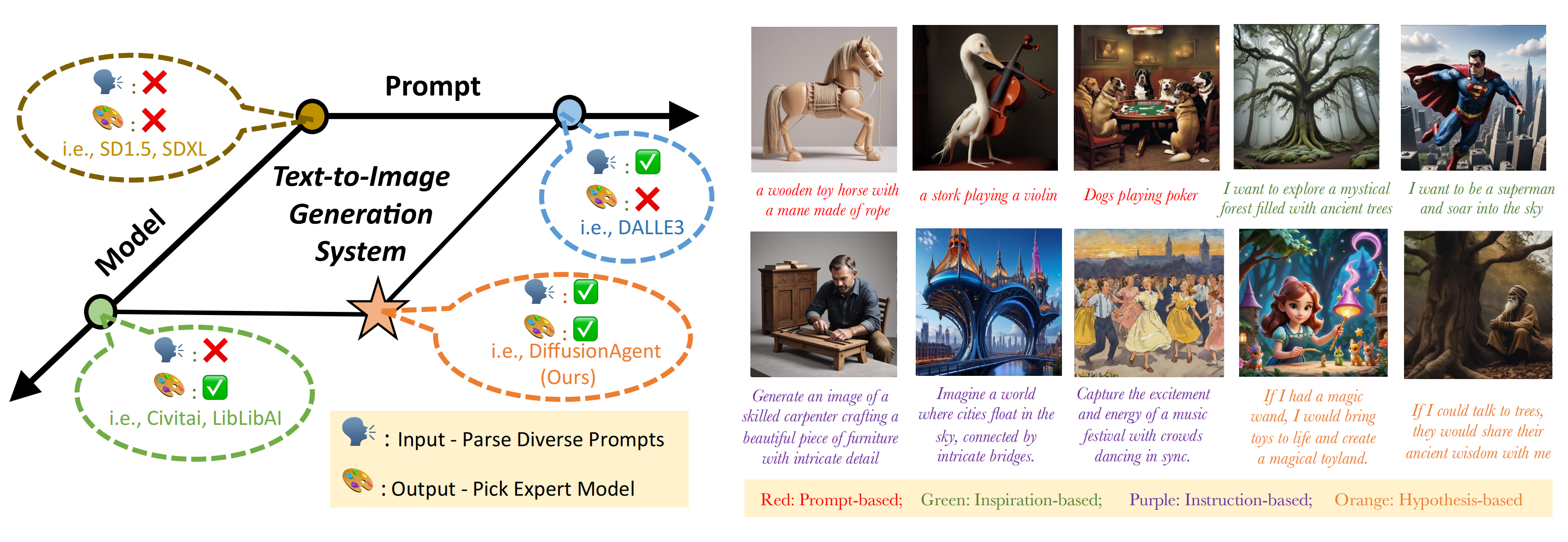
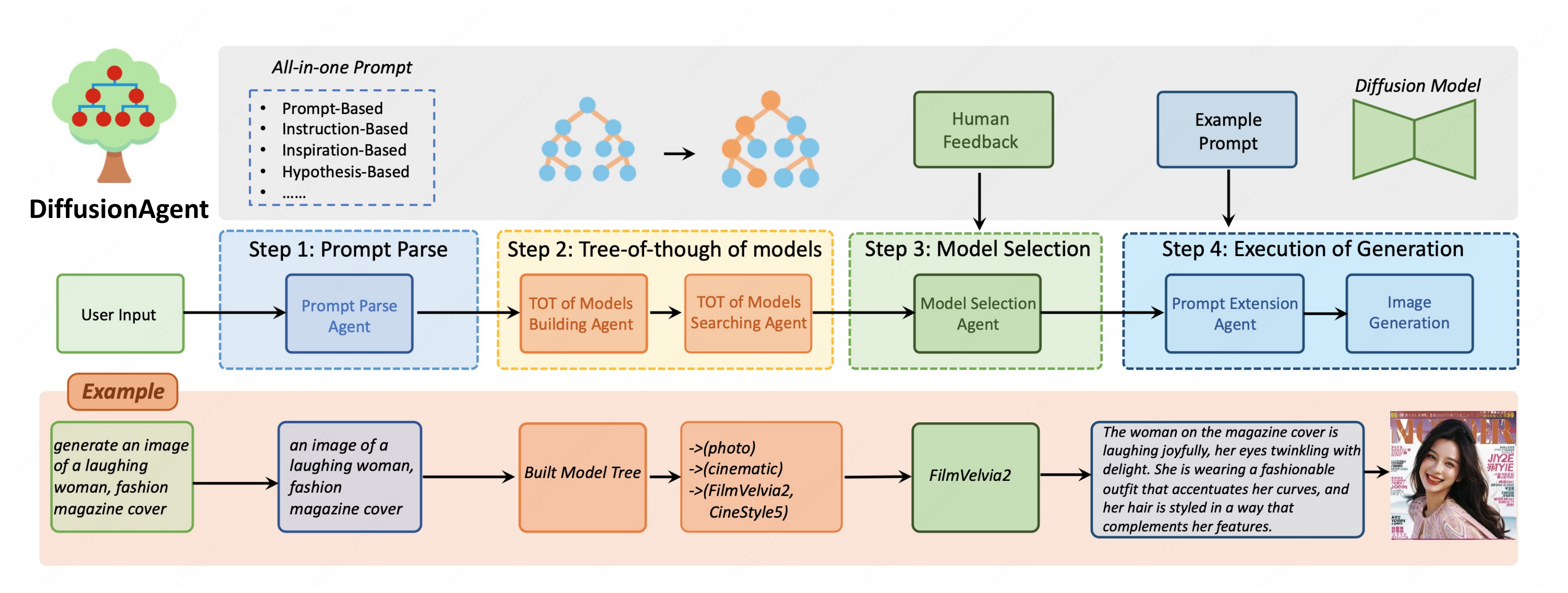
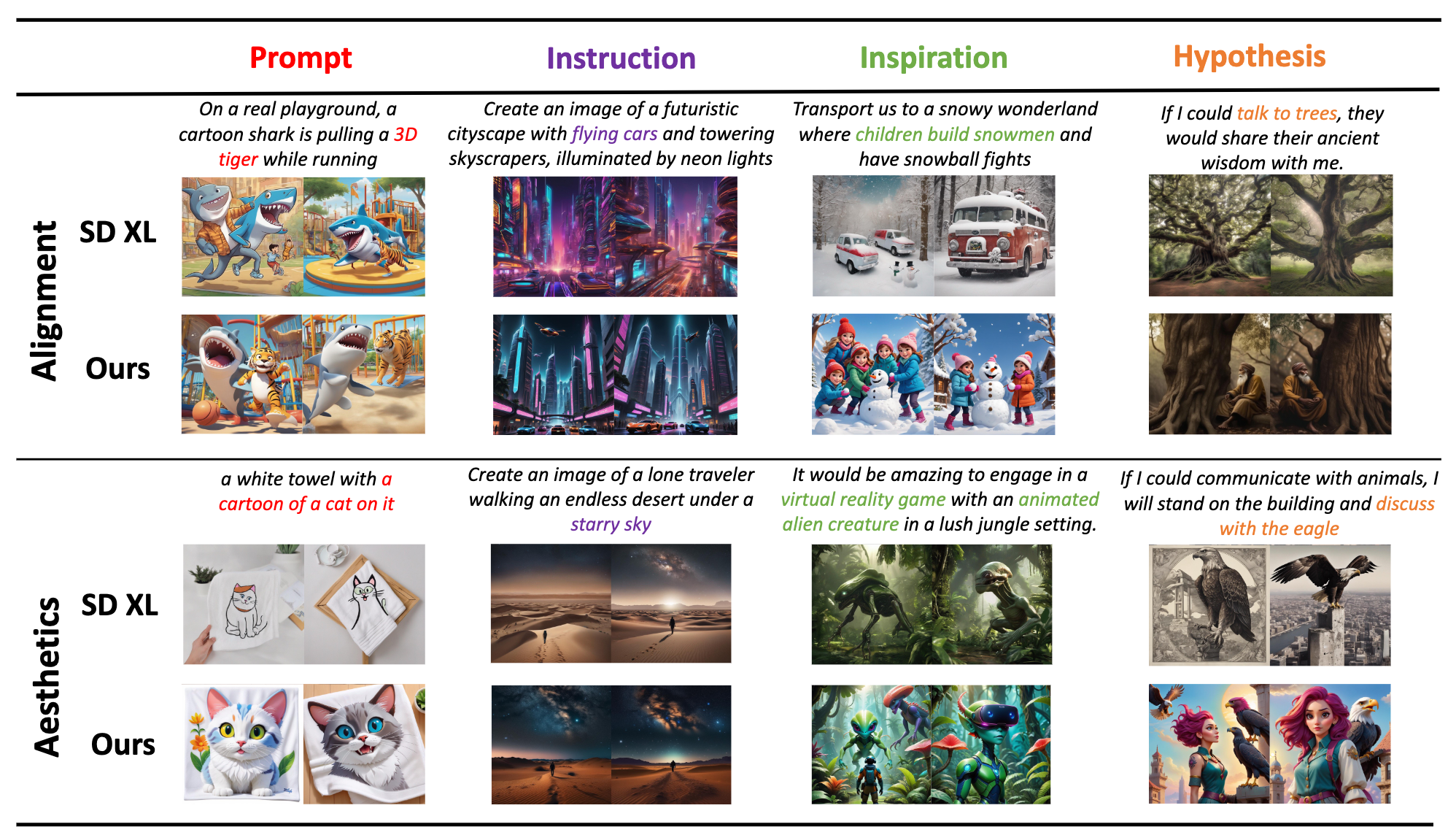
In the accelerating era of human-instructed visual content creation, diffusion models have demonstrated remarkable generative potential. Yet their deployment is constrained by a dual bottleneck: semantic ambiguity in diverse prompts and the narrow specialization of individual models. A single diffusion architecture struggles to maintain optimal performance across heterogeneous prompts, while conventional “parse-then-call” pipelines artificially separate semantic understanding from generative execution. To bridge this gap, we introduce DiffusionAgent, a unified, language-model-driven agent that casts the entire ``prompt comprehension–expert routing–image synthesis" loop into a agentic framework. Our contributions are three-fold: (1) a tree-of-thought-powered expert navigator that performs fine-grained semantic parsing and zero-shot matching to the most suitable diffusion model via an extensible prior-knowledge tree; (2) an advantage database updated with human-in-the-loop feedback, continually aligning model-selection policy with human aesthetic and semantic preferences; and (3) a fully decoupled agent architecture that activates the optimal generative path for open-domain prompts without retraining or fine-tuning any expert. Extensive experiments show that DiffusionAgent retains high generation quality while significantly broadening prompt coverage, establishing a new performance and generality benchmark for multi-domain image synthesis.
DiffusionAgent is an all-in-one system specifically designed to generate high-quality images for diverse input prompts. Its primary objective is to parse the input prompt and identify the generative model that produces the most optimal results, which is high-generalization, high-utility, and convenient. DiffusionAgent composes of a large language model (LLM) and various domain-expert generative models from the open-source communities (eg. Hugging Face, Civitai). The LLM assumes the role of the core controller and maintains the whole workflow of the system, which consists of four steps: Prompt Parse, Tree-of-thought of Models of Building and Searching, Model Selection with Human Feedback, and Execution of Generation.

@article{qin2024diffusionagent,
title={DiffusionAgent: Navigating Expert Models for Agentic Image Generation},
author={Qin, Jie and Wu, Jie and Chen, Weifeng and Yueming Lyu},
journal={arXiv preprint arXiv:2401.10061v2},
year={2024}
}